




Training Method Approach
Synthetic data is critical for making our system more robust to handle atypical cases, and you commonly see synthetic datasets for training other large vision-based AI models.
For AI training and inference, it is necessary for the training dataset to cover as many real world cases as possible. However, whereas most real-world datasets of humans are normally distributed, AI models based on these datasets weight in favor of the "average" person. Our approach strives to uniformly distribute subjects so that the model can better handle outlier cases just as well as typical cases.
Based on our experience collecting real-world samples of people for scanning, we run into the following limitations:
- Real-world collection efforts inherently result in normally distributed data, meaning that the model is weighted more towards typical body shapes and performs poorly for outliers. It is extraordinarily difficult or impossible to collect enough real-world test data to match all input cases to the system
- For real-world subjects, you typically get only one variation for each subject: one set of clothing, one skin tone, one hair shape, etc. So for a particular body, there is only one variation of that person and the model is not as robust as multiple variations per person. Alternatively there are real-world datasets with multiple clothing variations, but these result in lower number of body variations due to costs.
Our approach to training and validation set is to synthetically generate images of people based on the most diverse set of parameters. For body shape, we use the CAESAR database of posable body shapes comprised of over 4,000 3D-scanned individuals. We then sub sample this set to around 1000 input bodies that are uniformly distributed so that our AI model learns to handle atypical body shapes just as well as typical body shapes.
We then add skin, hair, and clothing to massively expand the number of training data. For skin tones, we generally follow the Monk Skin Tone Scale, so that the model learns to perform well for all skin tones. For clothing, we have a large database of tight-wear clothing that is uniformly randomized for each image.
Furthermore, we also randomize many aspects of the environment, including backgrounds, lighting, brightness, bloom, etc. And also aspects of the camera, primarily focal length and camera rotations.
Training Environment:
During the training phase, we generate 30,000-50,000 virtual bodies uniformly sampled from the CAESAR dataset. This approach ensures broad coverage of body variability rather than over-representing the dominant body types in the dataset.
By uniformly sampling across the full data range, we maintain a balanced distribution of body shapes and sizes.
To further increase variability and improve robustness to different scanning scenarios and camera configurations, we created the samples with variations in camera angles, lens intrinsics, lighting conditions, skin tones, and body poses.
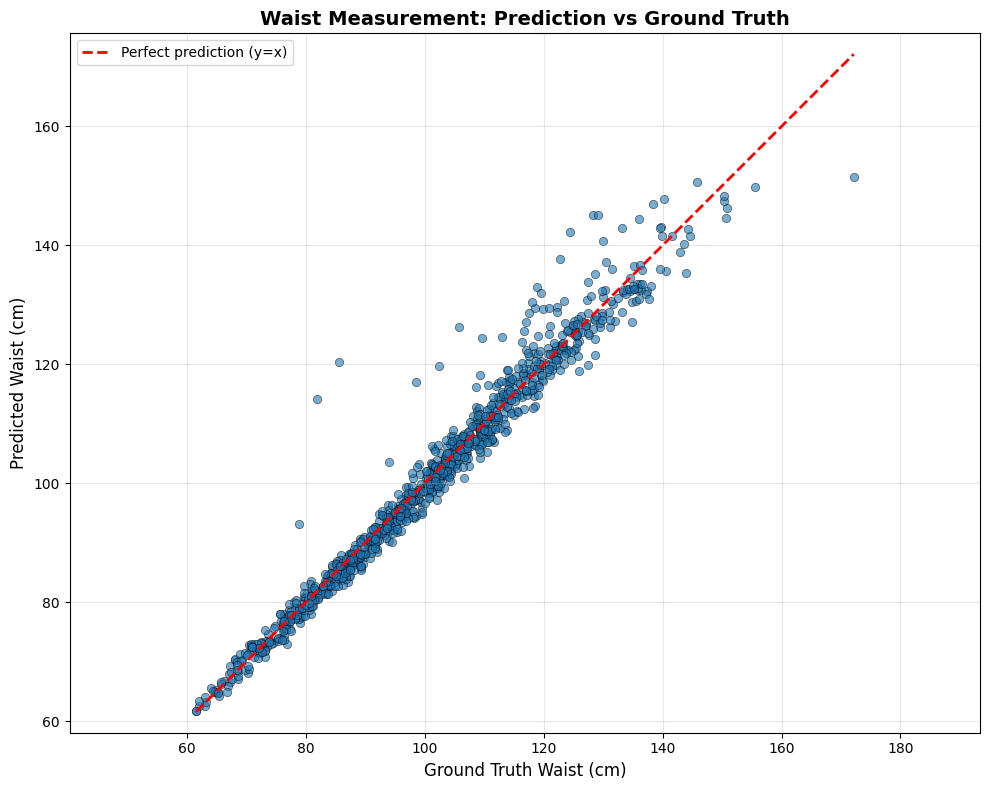
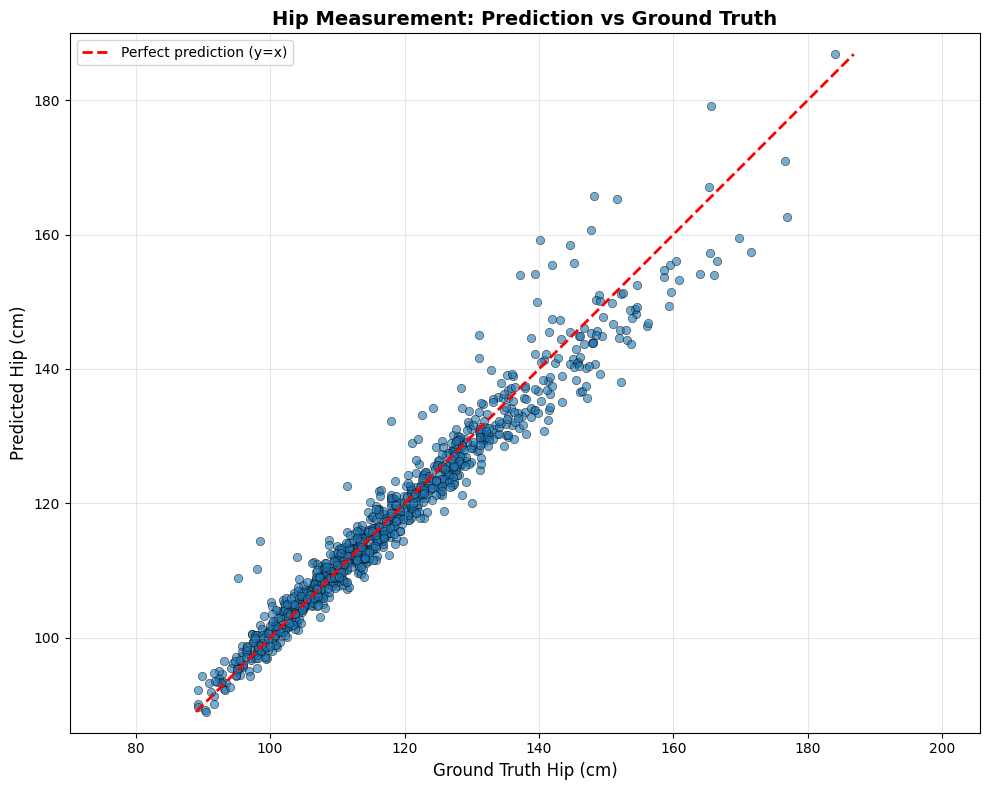
From the generated dataset, 70% of the samples are randomly selected for model training, while the remaining 30% are used for validation. The final model is selected based on the best validation performance.
Accuracy Evaluation Environment:
To ensure fair and unbiased evaluation, we use a separate set of 1,000 samples that were never included in the training or validation phases. This test dataset is also uniformly sampled to avoid overrepresentation of specific body types and includes different scanning scenarios and camera configurations. All reported accuracy metrics are based solely on this independent test dataset.
The entire process of training, validation, and testing is conducted exclusively using virtual data generated from the CAESAR dataset.









